Table Of Content

By using multiple observations before and after the intervention, the researcher can better understand the true value of the dependent variable in each participant before the intervention starts. Additionally, conducting multiple observations after the intervention allows the researcher to see whether the intervention had lasting effects on participants. Time series designs are similar to single-subjects designs, which we will discuss in Chapter 15.
Bridging the Evidence Gap in Obesity Prevention: A Framework to Inform Decision Making.
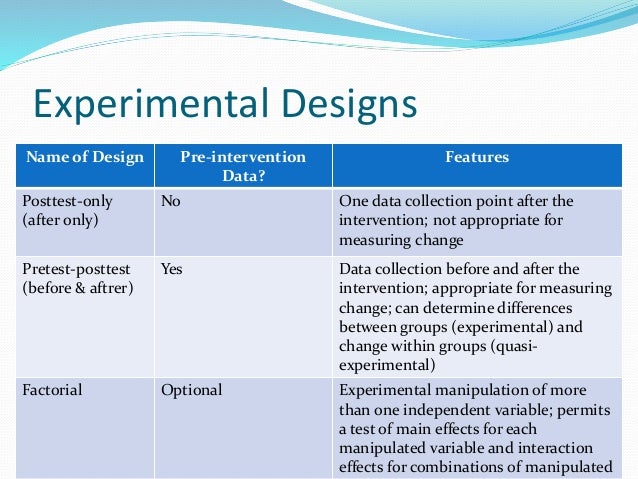
For example, organ transplants are allocated on the basis of a weighted combination of patient waiting time and the quality of the match of the available organ to the patient. Finally, unknown assignment rules commonly apply when units self-select into treatments or researchers give different treatments to preexisting groups (e.g., two communities, two school systems). A significant benefit of these types of designs is that they’re pretty easy to execute in a practice or agency setting. They don’t use comparison or control group, but they do examine outcomes for people who have gone through an intervention or been exposed to a condition. Below, we will go into some detail about the different types of pre-experimental design. Pre-experimental design refers to the simplest form of research design often used in the field of psychology, sociology, education, and other social sciences.
Chapter 5.2 Pre-Experimental Design
This study design, called a static group comparison, has the advantage of including a comparison group that did not experience the stimulus (in this case, the hurricane). Unfortunately, it is difficult to be sure that the groups are truly comparable because the experimental and control groups were determined by factors other than random assignment. Additionally, the design would only allow for posttests, unless one were lucky enough to be gathering the data already before Katrina.
Static-group comparison
In comparative experiments, animals are split into groups, and each group is subjected to different interventions, such as a drug or vehicle injection, or a surgical procedure. The sample size is the number of experimental units per group; identifying the experimental unit underpins the reliability of the experiment, but it is often incorrectly identified (Lazic et al. 2018). The experimental unit is the entity subjected to an intervention independently of all other units; it must be possible to assign any two experimental units to different comparison groups. For example, if the treatment is applied to individual mice by injection, the experimental unit may be the animal, in which case the number of experimental units per group and the number of animals per group is the same. However, if there is any contamination between mice within a cage, the treatment given to one mouse might influence other mice in that cage, and it would be more appropriate to subject all mice in one cage to the same treatment and treat the cage as the experimental unit. In another example, if the treatment is added to the water in a fish tank, two fish in the same tank cannot receive different treatments; thus the experimental unit is the tank, and the sample size is the number of tanks per group.
But other units of assignment are possible and should be entertained in some research contexts. Time can be the unit of assignment, as, for example, in some drug research in which short-acting drugs are introduced and withdrawn, or behavior modification interventions are introduced and withdrawn to study their effects on the behavior of single patients. Settings can be the unit of assignment, as when different community health settings are given different treatments, or different intersections are given different treatments (e.g., photo radar monitoring of speeding in a traffic safety study). In a study of the effectiveness of the Sesame Street program, for example, different sets of commonly used letters (e.g., [a, o, p, s] versus [e, i, r, t]) could be selected for inclusion in the program.
Insufficient or Incorrect Statistical Analysis

For example, Stratmann and Wille (2016) were interested in the effects of a state healthcare policy called Certificate of Need on the quality of hospitals. They clearly could not randomly assign states to adopt one set of policies or another. Instead, researchers used hospital referral regions, or the areas from which hospitals draw their patients, that spanned across state lines. Because the hospitals were in the same referral region, researchers could be pretty sure that the client characteristics were pretty similar.
Checks on the balance for each individual covariate can be performed, and propensity scores can be reestimated or specific controls for unbalanced covariates included in the statistical models. Finally, researchers can conduct sensitivity analyses to explore how much the results would change if important covariates were omitted from the propensity score model. Finally, if a researcher is unlikely to be able to identify a sample large enough to split into control and experimental groups, or if she simply doesn’t have access to a control group, the researcher might use a one-group pre-/posttest design.
One-shot case study design
The freedom of researchers to explore such innovative ideas is the lifeblood of preclinical science and should not be stifled by excessive constraints in terms of experimental design and conduct. This will also contribute to reducing research “waste” (Ioannidis et al. 2014; Macleod et al. 2014). Chapter “Resolving the Tension Between Exploration and Confirmation in Preclinical Biomedical Research” of the handbook will deal with exploratory and confirmatory studies in details.
It concludes with guidance on how to use theory, professional experience, and local wisdom to adapt the evidence gathered to local settings, populations, and times. As the name suggests, this type of pre-experimental design involves measurement only after an intervention. As in other pre-experimental designs, there is no comparison or control group; everyone receives the intervention (Figure 14.9). These are pre-experimental research design, true experimental research design, and quasi experimental research design. An important drawback of pre-experimental designs is that they are subject to numerous threats to their validity. Consequently, it is often difficult or impossible to dismiss rival hypotheses or explanations.
Reichardt provides a useful heuristic framework for expanding thinking about strong alternative research designs. When individuals are not the unit of analysis, however, complications may arise in the statistical analysis. As exploratory approaches, pre-experiments can be a cost-effective way to discern whether a potential explanation is worthy of further investigation.
The pre-experimental design will help researchers understand whether further investigation is necessary for the groups under observation. A benefit of this design over the previously discussed design is the inclusion of a pretest to determine baseline scores. To use this design in our study of college performance, we could compare college grades prior to gaining the work experience to the grades after completing a semester of work experience. We can now at least state whether a change in the outcome or dependent variable has taken place.
A Practitioner’s Guide To Interrupted Time Series by Leihua Ye, PhD - Towards Data Science
A Practitioner’s Guide To Interrupted Time Series by Leihua Ye, PhD.
Posted: Thu, 21 Nov 2019 08:00:00 GMT [source]
Proper modeling of the relationship between the assignment variable and the outcome permits a strong inference of a treatment effect if there is a discontinuity at the cutpoint. As implied by the preceding examples where we considered studying the impact of Hurricane Katrina, experiments do not necessarily need to take place in the controlled setting of a lab. Researchers using this design must be extremely cautious about making claims regarding the effect of the stimulus, though the design could be useful for exploratory studies aimed at testing one’s measures or the feasibility of further study. In our example of the study of the impact of Hurricane Katrina, a researcher using this design would test the impact of Katrina only among a community that was hit by the hurricane and not seek out a comparison group from a community that did not experience the hurricane. Three common types of pre-experimental designs include the one-shot case study, the one-group pretest-posttest design, and the static-group comparison. These designs offer a starting point for researchers but are typically seen as less reliable than more controlled experimental designs due to the lack of randomization and the potential for confounding variables.
These estimates can be useful for decision makers, who can estimate the change in costs of obesity that results from policy and other interventions aimed at changing the behaviors that result in obesity. However, the estimates produced by the incidence-based approach can be quite sensitive to assumptions about future costs, changes in health care delivery and technology, and the way future costs are discounted. An additional challenge relates to adequately controlling for the variety of other determinants of costs, that is, trying to estimate costs for a nonobese person so that the true excess costs resulting from obesity can be determined. Social welfare policy researchers like me often look for what are termed natural experiments, or situations in which comparable groups are created by differences that already occur in the real world. For example, Stratmann and Wille (2016) [2] were interested in the effects of a state healthcare policy called Certificate of Need on the quality of hospitals.
Experimental biases can cause significant weakness in the design, conduct and analysis of in vivo animal studies, which can produce misleading results and waste valuable resources. In biomedical research, many effects of interventions are fairly small, and small effects therefore are difficult to distinguish from experimental biases (Ioannidis et al. 2014). Therefore, it is imperative that biomedical researchers should spend efforts on improvements in the quality of their studies using the methods described in this chapter to reduce experimental biases which will lead to increased effect-to-bias ratio. In cases where the administration of a pretest is cost prohibitive or otherwise not possible, a one-shot case study design might be used.
There are more comprehensive planning guidelines specifically aiming at early experimental design stage. Most of them have been developed for a specific research field but carry ideas and principles that can be transferred to all forms of in vivo experiments. Notable are, for example, the very detailed Lambeth Conventions (Curtis et al. 2013) (developed for cardiac arrhythmia research), from Alzheimer’s research recommendations by Shineman et al. (2011) and generally applicable call by Landis et al. (2012). Wu and colleagues (2008a,b; see also West and Thoemmes, 2010) used these procedures in a study of the effect of retention in first grade on children’s subsequent math and reading achievement.








No comments:
Post a Comment